
Edo Interactive runs a card link offer platform which enables merchants to offer coupons to consumers based on their buying behavior.
The platform pulls around 50 million card transaction details from banks and credit card companies daily, runs them through a predictive model, and generates customized coupons which individual cardholders can redeem towards their next purchase.
For Edo, speed and accuracy of analytics is mission critical. In 2013 they faced a serious crisis when their existing data warehouse took 27 hours to process 24 hours worth of raw data.
To solve this problem Edo built a data lake using a Hadoop cluster which processes the daily build in 4 hours, and slashed the time needed to run models to minutes as opposed to days.
Data lakes: a new way to store big data
Data warehouses were the traditional repositories of enterprise data. Here’s how the process of data collection, storage and reporting looked like in a pre-Big Data environment.
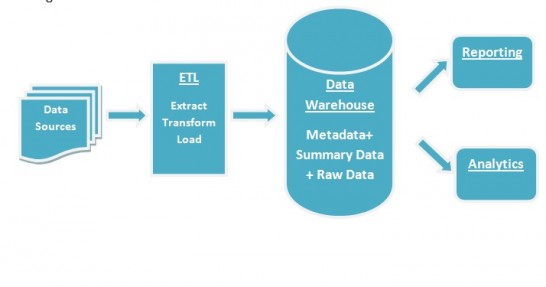
The data warehouse stores curated, scrubbed, and largely structured data from sources like ERP systems. Therefore the possibilities of analysis are limited.
In sharp contrasts here’s how Big Data is organized using data lakes.
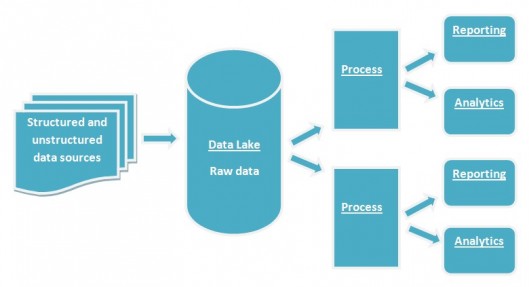
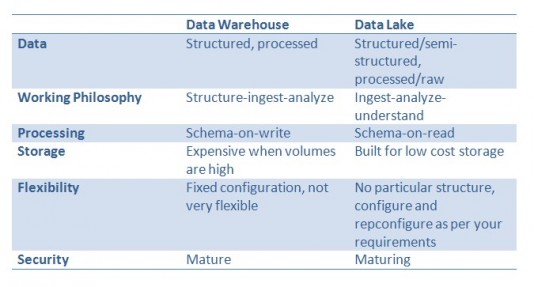
To sum up here are the differences between a data lake and a data warehouse:
Two of the biggest benefits of data lakes are speed and lower cost of hardware.
When Webtrends, a company which collects clickstream data from websites and mobiles which corporate marketers use to perform ad-hoc analysis implemented a data lake using a Hadoop cluster:
…Internet clickstream data (could) be streamed into the cluster and prepared for analysis in just 20 to 40 milliseconds…much faster than with the older system…hardware costs are (also) 25% to 50% lower on it.
Similarly, another company called Razorsight which offers cloud based analytics tools for telecommunication companies found that using a Hadoop cluster as a data lake cost $2,000 per TB, about one-tenth of their data warehousing solution.
But these benefits of flexibility, cost, and speed are only realized if the data lake architecture is well designed, and if there are rules in place governing how data is stored.
Preventing a data lake from becoming a data dump
While a data lake will hold unstructured or raw data it in itself cannot be a data dump like a badly managed Sharepoint portal.
Data lakes need a fair amount of governance because of the nature of data stored in the former.
A data lake works on the ingest-analyze-understand philosophy.
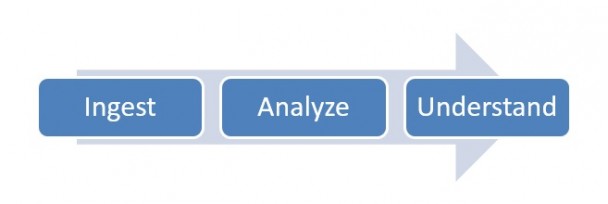
Many flawed data lake implementations focus exclusively on the Ingest phase. When that happens, disaster strikes. In the case of one company:
“All of the context of the data — where it came from, why it was created, who created it — was lost…By the time the company fixed this issue and went back to their old platform, they had lost two-thirds of their customers and almost went out of business.”
That would scare anyone off data lakes.
If you want to keep your data lake from becoming a data sinkhole:
- Manage metadata: Keeping the metadata intact answers questions like what is the source of the data and what does the data represent. Metadata critical to meaningful analysis. In this context a data dictioniary is also a valuable tool.
- Catalog data: Without a data catalog analysts would be hard pressed to find out the right data from the hundreds of terabytes or scores of petabytes of data in a typical data lake.
- Index data: As a dataset increases indexing becomes vital for fast and speedy retrieval of data.
Adopting a schema for data lakes will also maintain data lineage which is extremely imprtant in regulated industries like finance and healthcare.
Conclusion
Data lakes offer unprecented flexibility for data driven companies to suss out insights that would have been otherwise impossible with traditional data warehouses.
Data lakes are particularly suitable when you need to store massive amounts of unstructured data like tweets along with structured data like server logs but don’t want them to be in silos.
However without a proper architecture a data lake becomes a data dump, and all you will have is a case of garbage-in garbage-out.









